如何设计一个可靠数据传输协议?
本文是我个人对 《Computer Networking: A Top-down Approach》3.4 节的总结。
让我们想象这样一个传输数据的管道:
1. 管道中的数据不会被“污染”。
2. 管道中的数据不会被传丢。
3. 管道中的数据总是按照发送的顺序被接收者接收的。
满足以上三个条件,就可以被认为是可靠的数据传输。似乎看起来挺简单,是吧?
但当这种可靠数据传输建立在不可靠的基础(Internet Protocol)之上时,这问题就开始难了。
本文所提到的数据传输皆为单向传输。
Reliable Data Transfer 1.0
这里补充个关于有限状态机的小知识: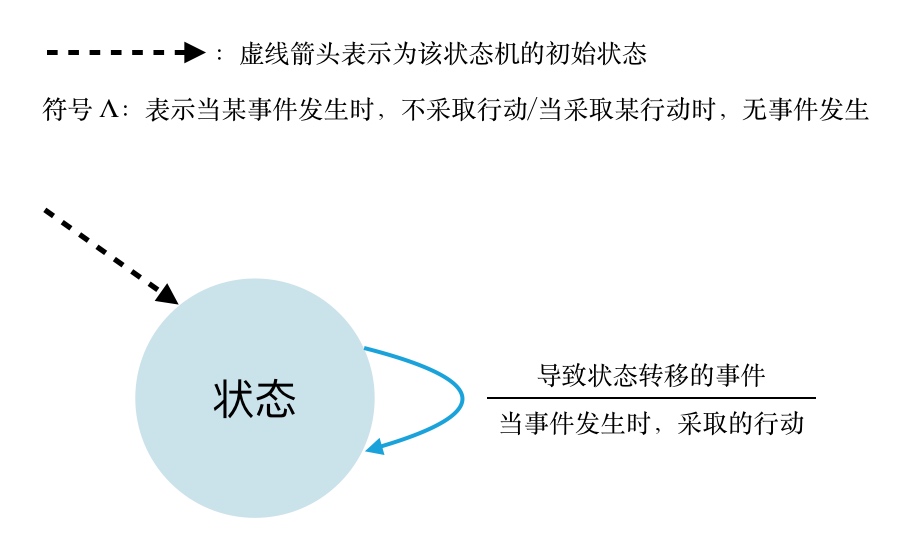
在 1.0 版本里,假设要打造的可靠传输管道也是建立在一个可靠传输管道之上的。
我们可以用有限状态机来表示 sender 和 receiver: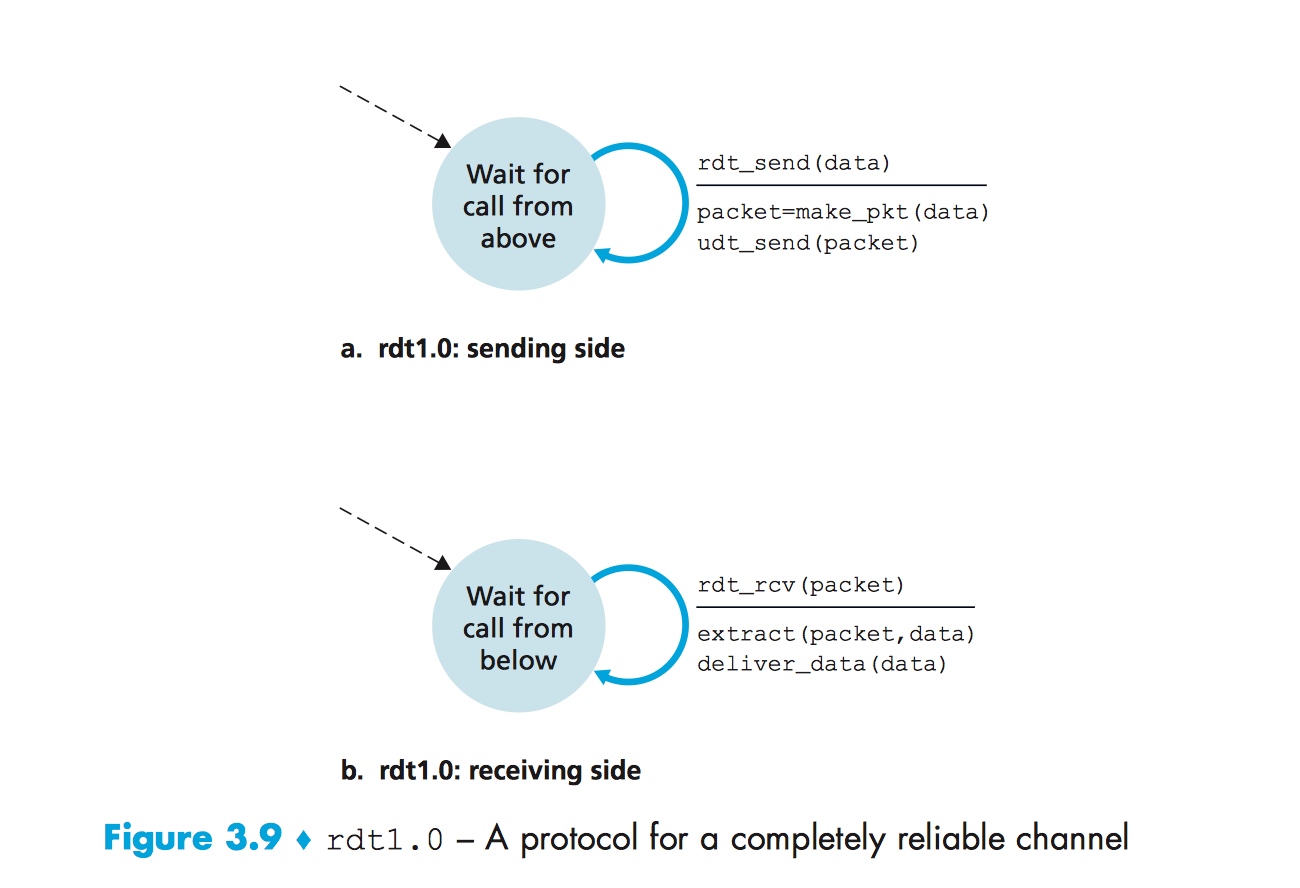
rdt 1.0 sender 在收到发送数据的事件(rdt_send(data))后,把数据分割为一个一个 packet,并开始发送数据。rdt 1.0 receiver 在收到接收数据的事件(rdt_rcv(packet))后,从 packet 中提取数据,并把数据发给上层。
在多种假设之下,rdt 1.0 的设计很简单,也很可靠。这里也隐含了 receiver 的接收速度能与 sender 的发送速度同步。
Reliable Data Transfer 2.0
不得不说,rdt 1.0 的实现条件极为苛刻,过于理想了。更加具有现实意义的是:传输过程中的数据可能会被“污染”,如位翻转。起初的假设由三个变为两个了。
再进一步讨论 rdt 2.0 的细节之前,让我们设想一个生活中常出现的场景:张三正在跟李四打电话。当李四说完一个事之后,张三清楚听到之后会回复一句“好的”。但当张三未能听清楚李四所说的事情时,张三会回复一句“能不能再说一遍?我没听清楚”。
“好的”可以视为 positive acknowledgments,“能不能再说一遍?我没听清楚”可以视为 negative acknowledgments。Receiver(张三)可以利用这两种信息使 sender(李四)明白:哪条信息已经传达到位和哪条信息需要重传。在计算机网络的范畴内,基于类似重传机制的可靠数据传输协议被称为自动重复请求协议(Automatic Repeat reQuest protocols)。
那么如何实现 ARQ 这个协议呢?
- receiver 要有检测数据是否出错(被污染)的能力,如添加校验和(checksum)字段。
- receiver 要有发送传输反馈的能力,如上文提到的 ACK(positive acknowledgment)和 NAK(negative acknowledgments)。
- 在 receiver 收到一个出错的数据后,sender 要有重新发送该数据的能力。
下图是 rdt 2.0 的有限状态机表示: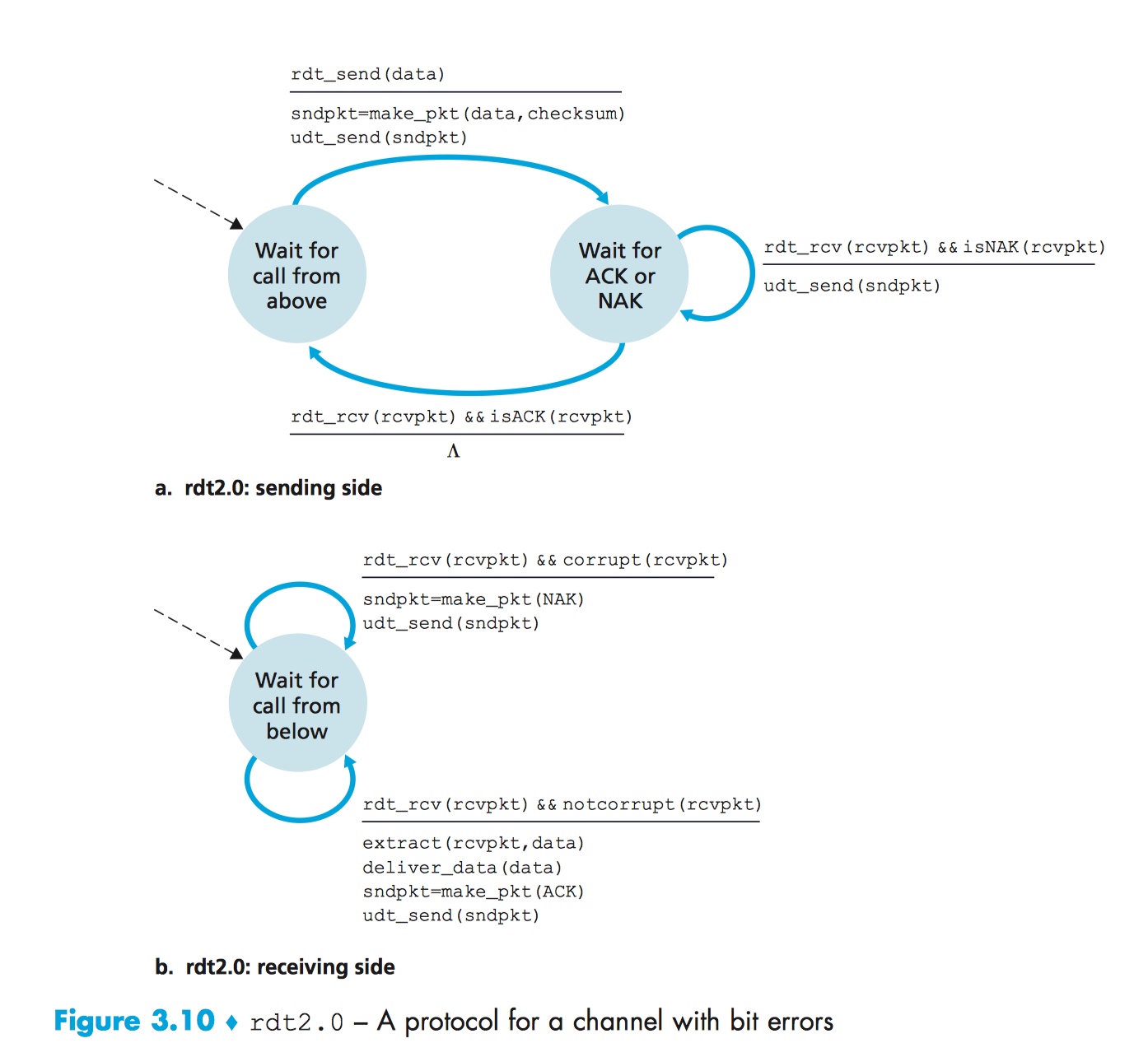
rdt 2.0 sender 在收到 NAK 时,会重新发送最近刚发送过的数据,并继续等待 receiver 对此重发数据的回应。需要注意的是:当 sender 处于 Wait for ACK or NAK 状态时,rdt_send(data) 事件不会出现。换句话说,只有 sender 离开 Wait for ACK or NAK 状态之后,才能响应 rdt_send(data) 事件。
因此,除非 sender 确认 receiver 已经正确地收到它当前发送的数据,sender 是不会发送新数据的。像 rdt 2.0 类似这样的行为特征,我们称之为停止等待协议(stop-and-wait protocol)。
Reliable Data Transfer 2.1
目前为止,rdt 2.0 看起来不错哟,但其实它有一个致命的问题:假如 sender 收到的 ACK/NAK 被“污染”了,sender 是没有办法知道 receiver 是否正确收到它发送的最后一块数据!
那么该如何处理这种情况呢?
- 添加足够多的校验和比特位,使得 sender 不仅能检测到数据出错,而且能把错误数据恢复过来。
- 当 sender 收到被“污染”的 ACK/NAK 时,它就直接重新发送当前的数据。但这又会引入一个新问题——重复数据包(duplicate packets)。receiver 没有办法确认 sender 是否正确收到它发送的 ACK/NAK,因此它也没法判断下一个到来的数据包是新的数据还是重传的旧数据。
我们选择第二种方法,对于重复数据包这个新问题,有个简单的解决方法:在数据包首部添加序列号字段。这样,receiver 可以利用数据包的序列号来判断下一个到来的数据包是新的数据还是重传的旧数据了!rdt 2.0 作为停止等待协议的一个简单实现,序列号字段长为 1 位就够了。
目前仍是假设这个数据传输管道是不会传丢数据的,所以 ACK/NAK 数据包是无需使用序列号来表示它们是对某个数据包的回应。


Reliable Data Transfer 2.2
rdt 2.1 在 sender 和 receiver 均使用了 ACK/NAK。当失序数据到达 receiver 时,receiver 发送 ACK。当被“污染”的数据到达 receiver 时,receiver 发送 NAK。我们尝试换一种思路:当被“污染”的数据到达 receiver 时,receiver 不发送 NAK,取而代之的是发送一个对最近正确收到的数据的 ACK。
那当 sender 收到这个 ACK 时,它该怎么判断这个 ACK 是代表 receiver 正确接受了它刚发送的数据(实则在路途中被“污染”)还是代表 receiver 正确接受了它上一个发送的数据呢?这种情况下,ACK 数据包也需要加入序列号了。
当 sender 收到两个对同一个数据包确认的 ACK 时,即收到重复的 ACK,sender 就可以意识到:receiver 没能正确收到被确认两次的数据包的下一个数据包!
这样就迎来了 NAK-free 的 rdt 2.2!
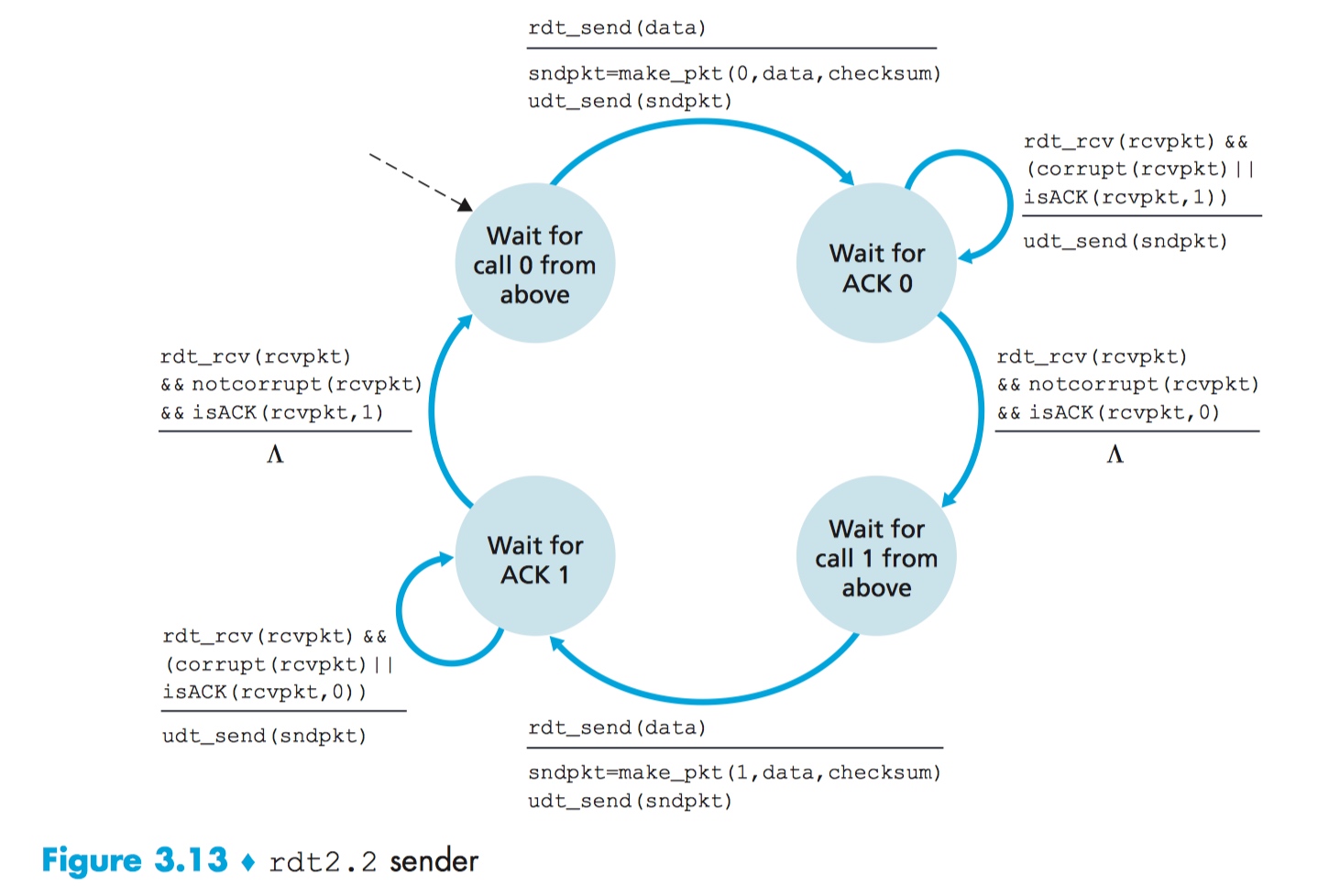
rdt 2.2 和 rdt 2.1 的区别在于:sender 现在必须得在发送 ACK 时,添加对应的序列号了。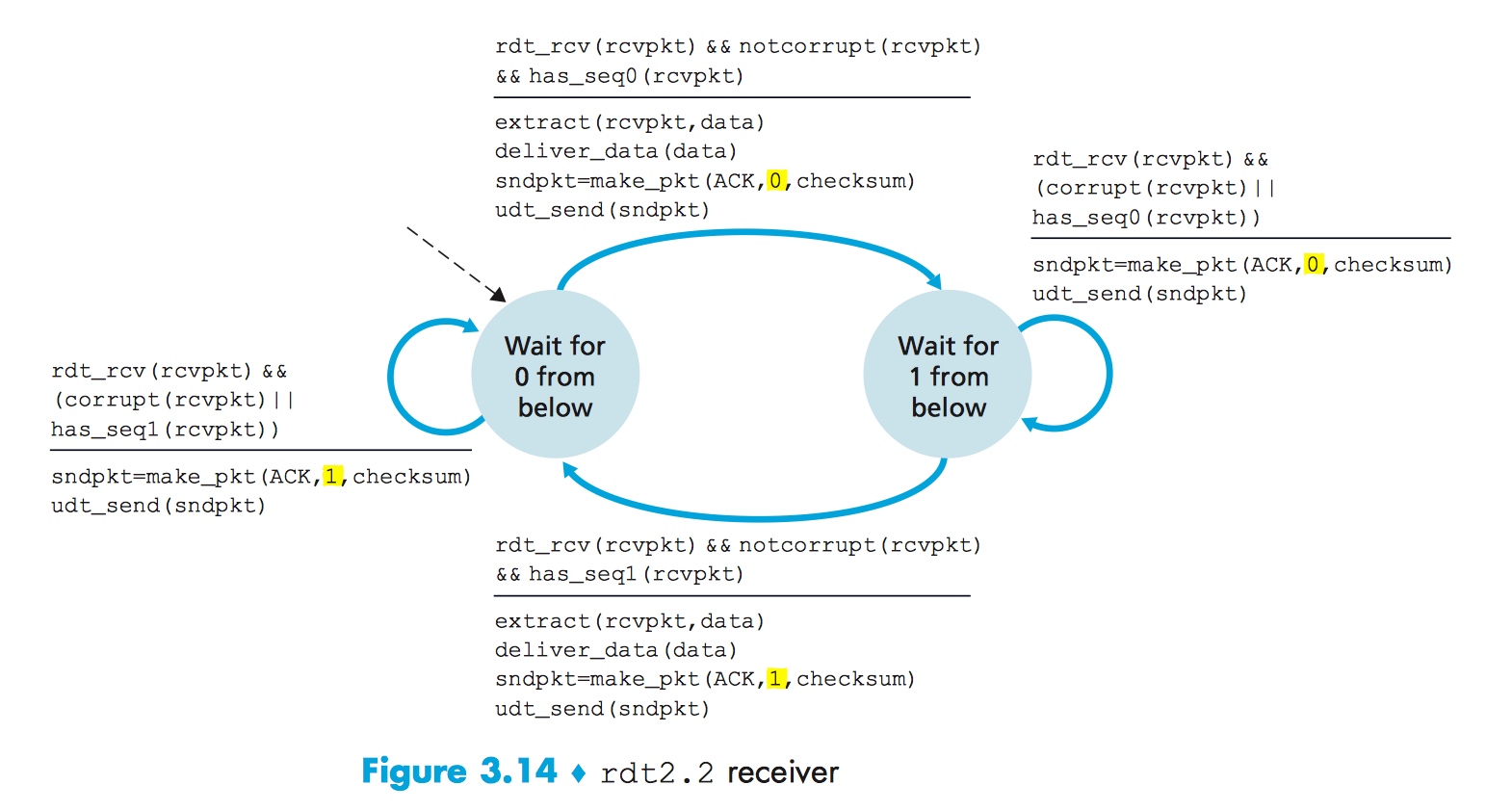
Reliable Data Transfer 3.0
在真实世界里,数据随时都有可能传丢。
对于一个可靠数据传输协议来说,它必须解决:
- 如何检测数据传丢了?
- 当数据传丢了,它该做什么?
rdt 2.2 很好地替我们回应了第二个问题。
有不少的方法来解决第一个问题,但在这里,我们把检测数据丢失和数据恢复的重担放在 sender。
设想这样一个场景:sender 把数据发送出去,第一种情况:数据在发送途中丢失了。第二种情况:receiver 发回的 ACK 丢失了。在这其中任意一种情况下,sender 均不会收到关于刚刚发送出去的数据的任何反馈。但是,如果 sender 可以等足够久,以至于它可以很肯定:刚发出去的数据丢了,这样它就可以直接重新发送这个数据。
至于这个等待时间是多少,我们可以暂且理解为:一个 RTT(Round Trip Time)加上在物理介质上传输该数据的时间。
需要注意的是:如果一个数据包经历了一个特别大的延迟(网络特别拥堵),即使数据包和它的 ACK 都没有丢失,sender 也会重新发送数据包。我们就又遇到在 rdt 2.0 中遇到的老问题——重复数据包。没关系,rdt 2.2 已经妥善处理好这个问题了。
当遇到以下情况时:
- 发出的数据在途中丢了
- receiver 发回的 ACK 丢了
- 发出的数据或它的 ACK 经历了很大的延迟(网络特别拥堵)
从 sender 的角度看,重新发送数据是万能灵药。为了实现基于时间的重传机制,我们需要一个倒计时器。
这个倒计时器在计时结束后中断 sender。在发生中断后,sender 需要采取以下三种行为:
- 无论是第一次发送某个数据,还是重传某个数据,重置计时器,重新开始计时。
- 响应计时中断,并采取恰当的行动。
- 暂停计时。
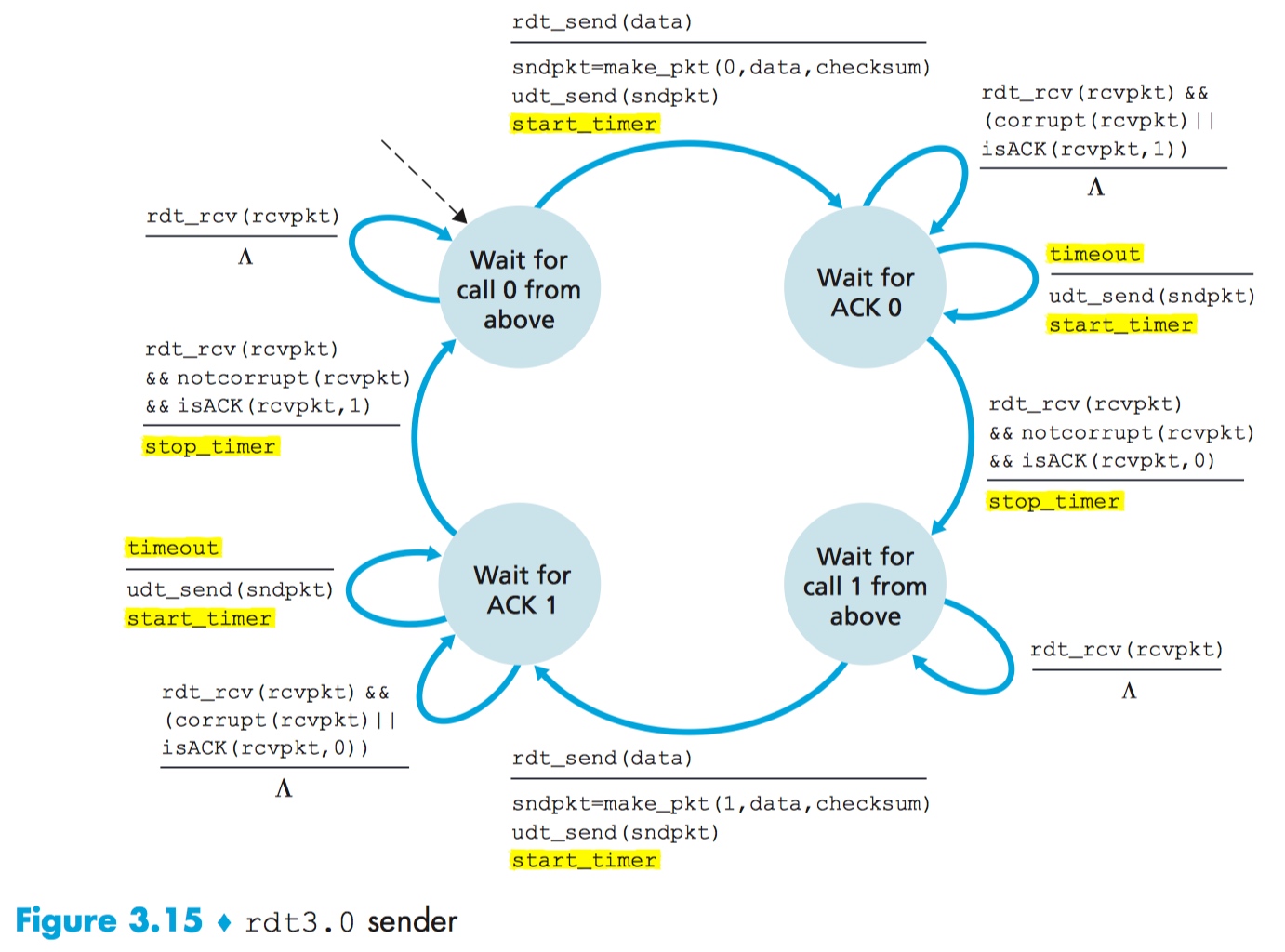
到这里,我们已经有个可用的可靠数据传输协议了!
那性能怎么样呢?

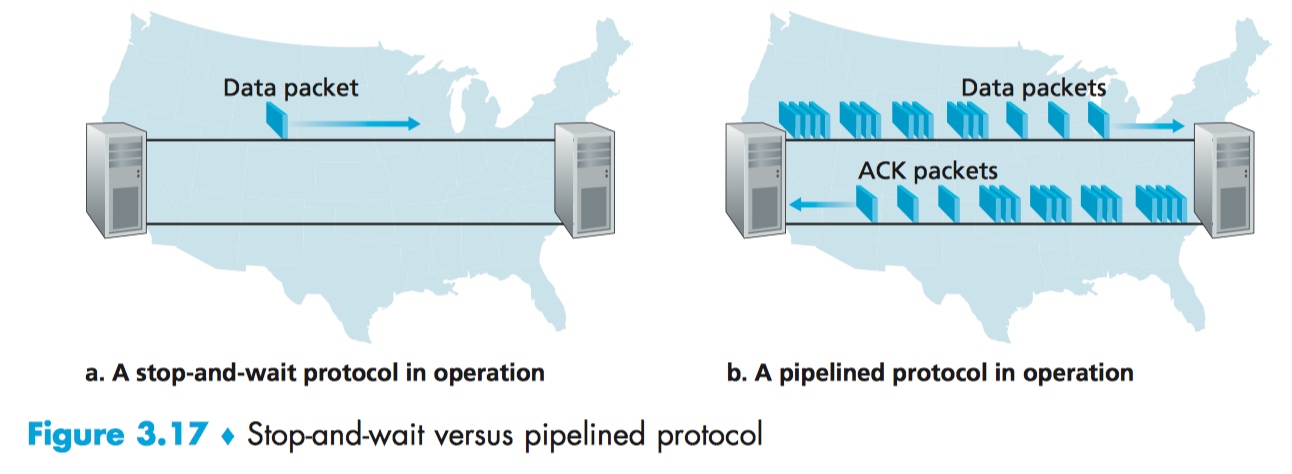
看完上图,直觉告诉我们可以像流水线般同时发送好几个数据包,以提高吞吐量。
要实现如图所示的流水线式发送,需要做到:
- 因为每个在传送途中(非重传)的数据包需要独一无二的序列号,且同时会存在多个在传送途中的未被确认的数据包,所以序列号的范围得是递增的。
- sender 和 receiver 可能会需要缓存多个数据包。sender 至少得缓存已经传送在途且未收到确认的数据包。
- 根据一个可靠数据传输协议如何应对:1. 数据传丢;2. 数据被”污染”;3. 数据因网络拥堵而迟到;这三种问题,大体可以分为两种错误恢复的方法:
- GBN(Go-Back-N)
- 选择重传(selective repeat)
GBN
在 GBN 协议中,sender 可以在不需要等待收到 ACK 的情况下,同时发送 N 个数据包,这意味着 sender 最多能保持 N 个未收到 ACK 的数据包,N 也被称为滑动窗口的大小。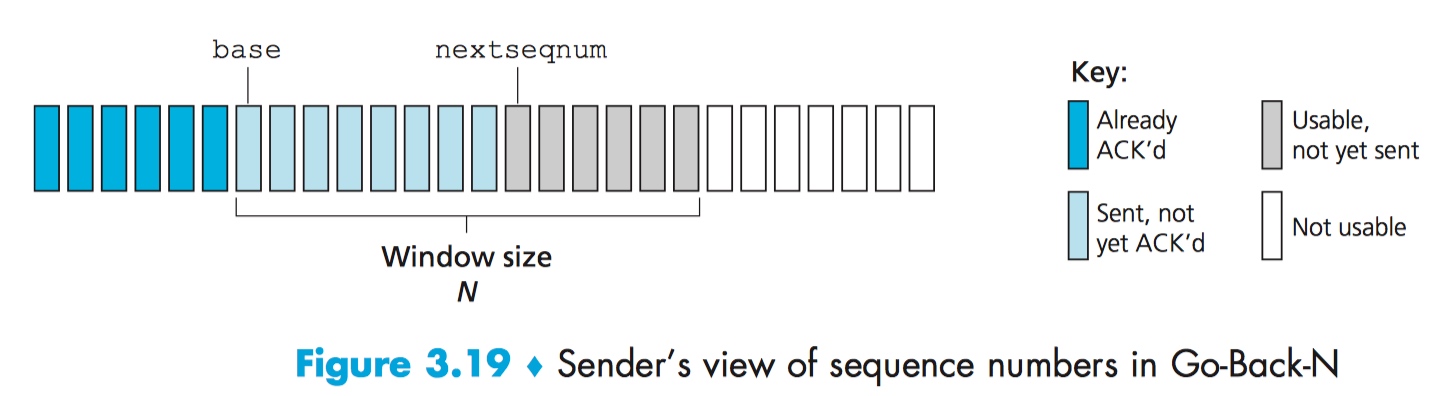
图中的 base 意为:序列号最小的未收到 ACK 的数据包的序列号,而nextseqnum 意为:下一个将被发送的数据包的序列号。
区间 [0, base - 1] 表示为:序列号落在此区间的数据包均被发送和成功收到 ACK。
区间 [base, nextseqnum - 1] 表示为:序列号落在此区间的数据包均被发送且还未收到对应的 ACK。
区间 [nextseqnum, base + N - 1] 表示为:序列号落在此区间的数据包均可立即被发送。
区间 [base + N, 正无穷] 表示:序列号落在此区间的数据包处于等待发送状态。当序列号为 base 的数据包收到 ACK 之后,整个滑动窗口 N 向后移动,这样序列号 base + N 的数据包才可以被发送。
下图为 GBN sender 有限状态机表示: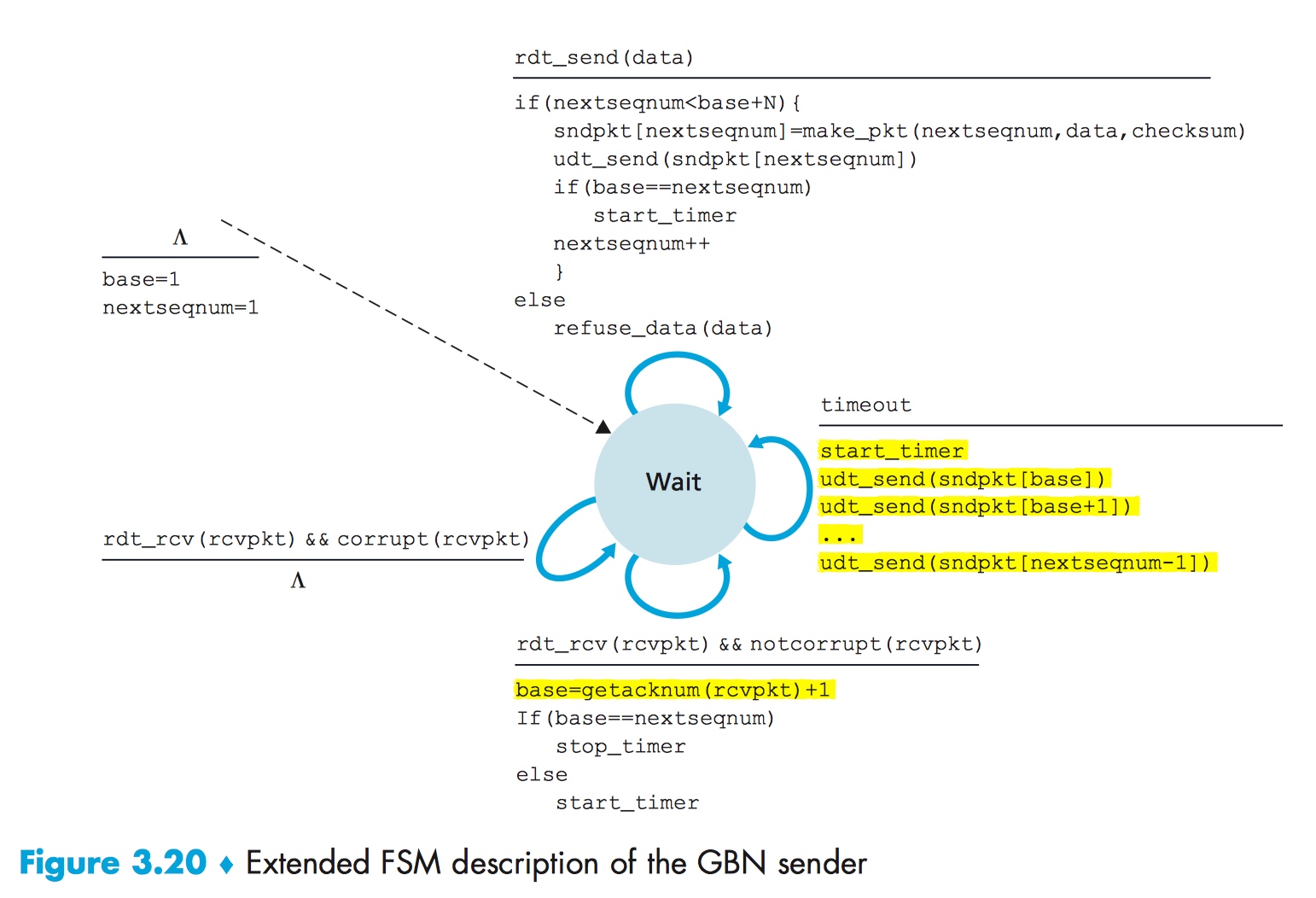
当 sender 的上层调用 rdt_send() 时,sender 会首先检查窗口是否已满,如果窗口已满,则拒绝发送数据。
当超时事件发生时,sender 启动计时器,且重新发送所有之前已发送过但未收到 ACK 的数据包。
当收到某个数据包的 ACK 时,还有已被发送且未收到 ACK 的数据包,sender 需要重启计时器;如果此时不存在已被发送且未收到 ACK 的数据包,sender 需停止计时。
下图为 GBN receiver 有限状态机表示:
假设 receiver 已经接受了前 n - 1 个数据包,那么 receiver 下一个就想收到序列号为 n 的数据包。receiver 会抛弃所有下一个到来的序列号非 n 的数据包,并重新发送最近收到的数据包的 ACK(在这个例子中为:ACK n-1)。这就是累计确认(cumulative acknowledgments)。
GBN 中的 receiver 拒绝接受失序的数据包,这听起来虽然有点蠢,似乎不尊重 sender 的辛苦劳动,但这样做还是有原因的。
假设 receiver 现在正恭迎序列号为 n 的数据包的到来,但序列号为 n + 1 的小老弟先来了,打了一个措手不及。因为收到的数据必须按顺序组装起来,所以此时的 receiver 选择把序列号为 n + 1 的数据包缓存起来。但是当序列号为 n 的数据包丢了之后,根据 sender 重传的规则,序列号为 n 和 n + 1 的数据包都会被重传。这样就能理解 receiver 不缓存失序数据包的原因了,反正都要一起重传过来的嘛,缓存干嘛!
这样,sender 需要记住自己滑动窗口的上下界和下一个要发送的数据包的位置就可以,而 receiver 这边就更简单了,只需记住自己所期待到来的那个数据包的序列号就行了。
当然,这种丢掉正确收到却失序的数据包的做法也是有缺点的,因为之后的重传过来的数据包可能会被传丢或被“污染”,这样就会导致更多的数据重传。
选择重传(Selective Repeat)
流水线式的同时发送多个数据包的 GBN 协议已经比之前谈论的停止等待协议强不少。但是也有一些场景下,GBN 同样因为性能被人诟病。
特别是当前网络的带宽延时乘积很大且滑动窗口 N 也很大时,某个数据包传输出错会导致 GBN sender 重传一大堆的数据包,这大部分情况是没有必要的。随着数据传输出错率变高,滑动窗口中便会塞满大量重传的数据。
让我们来看一看选择重传协议。正如其名,选择重传会避免像 GBN 那样的没必要的大量重传,它只选择性地重新发送它认为没能正确送达的数据包!
与 GBN 不同的是,它的滑动窗口里会出现一些被 ACK 过的数据包,换句话说,不管这个被正确收到的数据包是不是失序的,SR 均会确认这些数据包。失序的数据包将会被缓存起来。


尤其要注意 receiver 图里的第二点:当收到已经被 ACK 过的数据包时,receiver 不能直接忽略这个数据包,仍需发送对应的 ACK。
但这样做的原因是什么呢?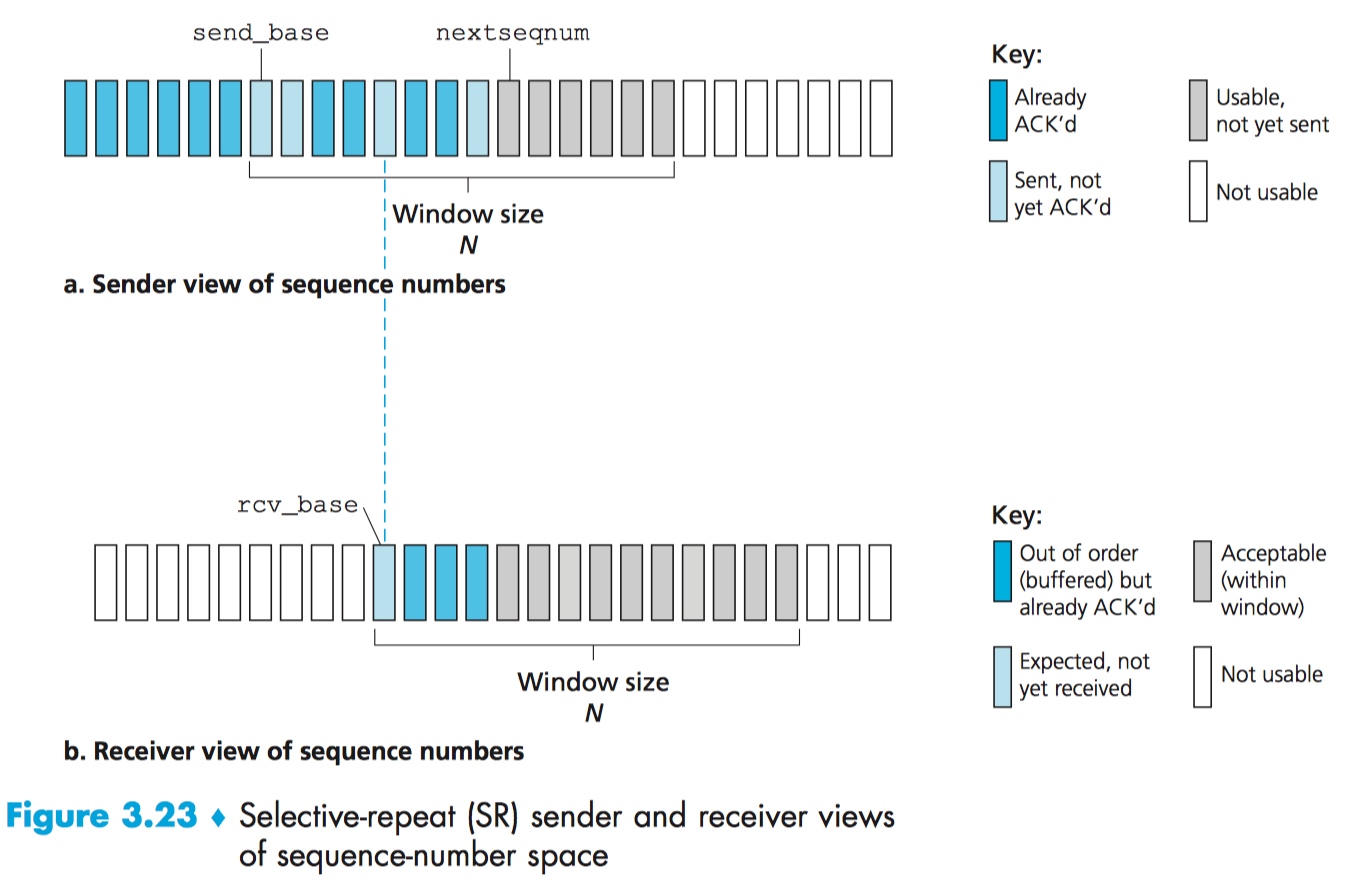
参照上图,设想一个场景:序列号为 send_base 的数据包已经被 receiver ACK 了,但发回 sender 的 ACK 半途丢了。计时器时间一到,sender 仍未收到 send_base 数据包的 ACK,sender 有正当理由怀疑这个数据包未能成功送达,并开始选择重传这个数据包。如果在这种情况下,receiver 选择忽略这个数据包,那么 sender 的滑动窗口永远不会向后移动!
这个例子说明 SR 协议一个很重要的特点:对某个数据包是否被正确收到,SR 中的 sender 和 receiver 分别持有不同的观点。
Sender 和 receiver 之间这种“不同步性”在序列号范围有限的现实面前有重要的后果。
考虑场景 A:有限的序列号范围是: {0, 1, 2, 3},滑动窗口大小为 3。如下图所示,数据包从 0 到 2 均成功被 receiver 收到。但这三个数据包对应的 ACK 都传丢了。时间一到,sender 开始重传数据包 0。Receiver 成功收到了数据包 0。此时这个数据包 0 是发送的第一个数据包的拷贝。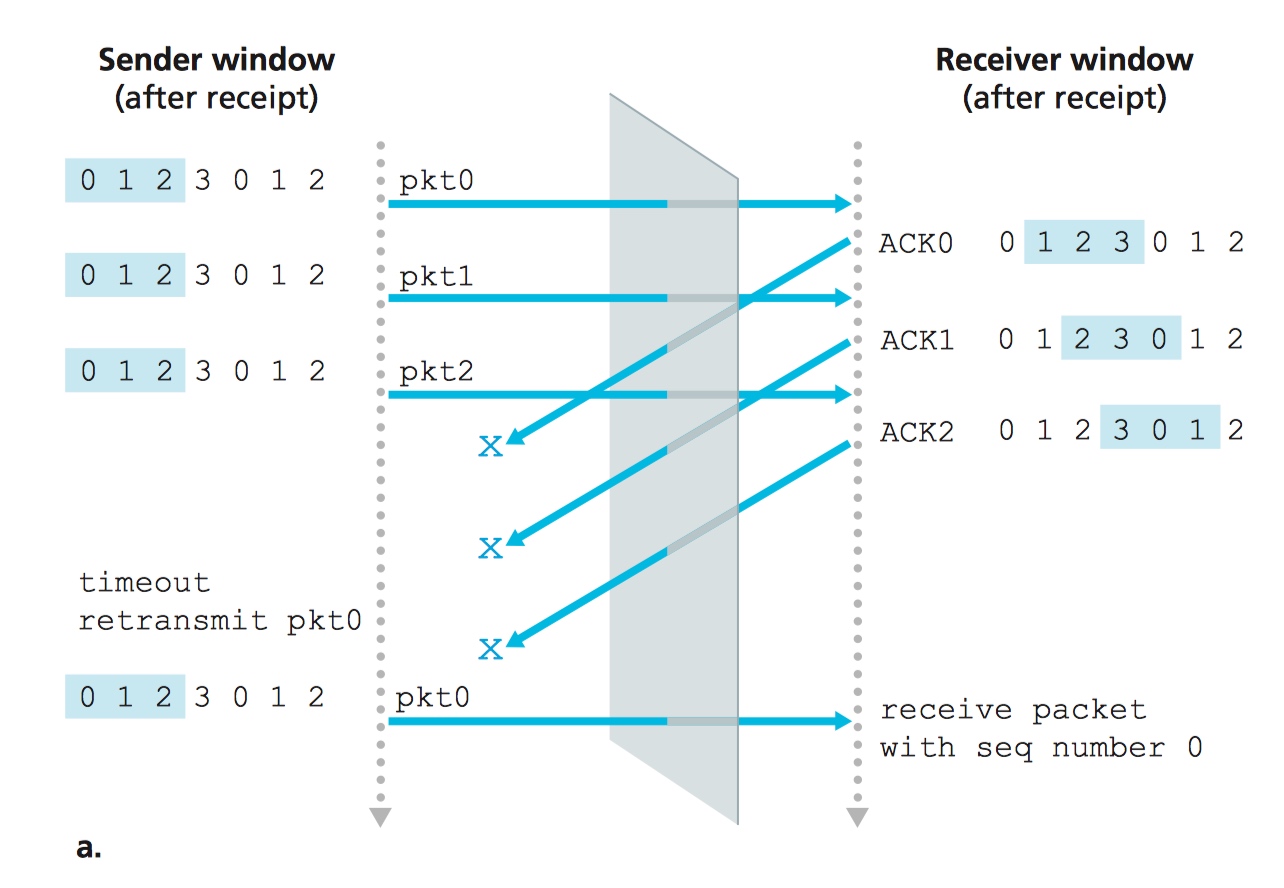
考虑场景 B:ACK 从 0 到 2 均被 sender 成功收到。当收到 ACK 0 时,sender 开始发送数据包 3。当收到 ACK 1 时,sender 开始发送数据包 0。
Receiver 也成功收到数据包 0。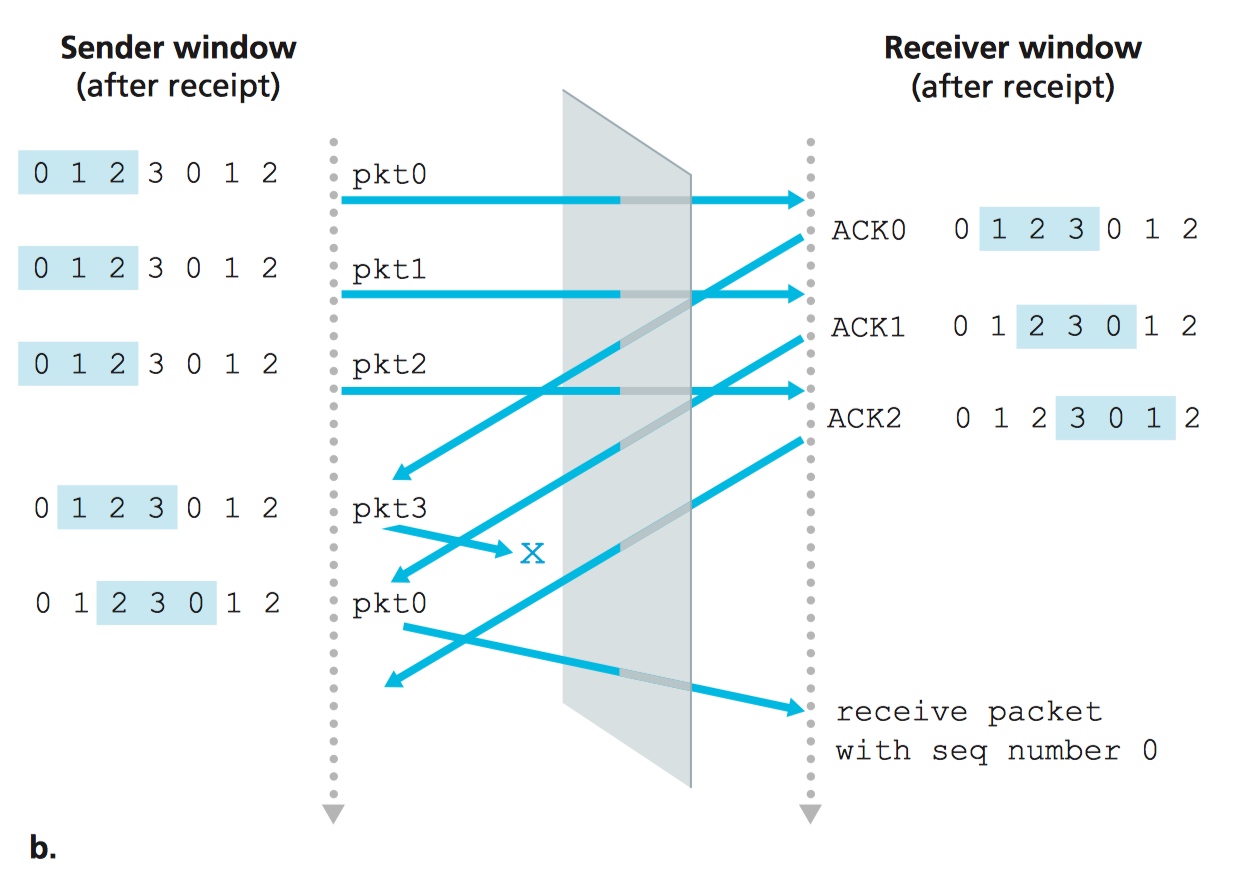
Receiver 是没法看到 sender 的行为的,所以可以想象,receiver 和 sender 之间存在“看不见的铁幕”。现在,请从 receiver 的角度考虑场景 A 和 B。对于 receiver 来说,场景 A 和场景 B 是一模一样的,然而站在上帝视角的我们能很轻易地分辨出 A 与 B 之间的不同。
Receiver 是没法分辨出它刚收到的数据包 0 到底是第五个数据包还是第一个数据包的拷贝。所以当滑动窗口的大小等于序列号个数减一时,这一切都行不通了。
那把窗口大小改为 2 呢?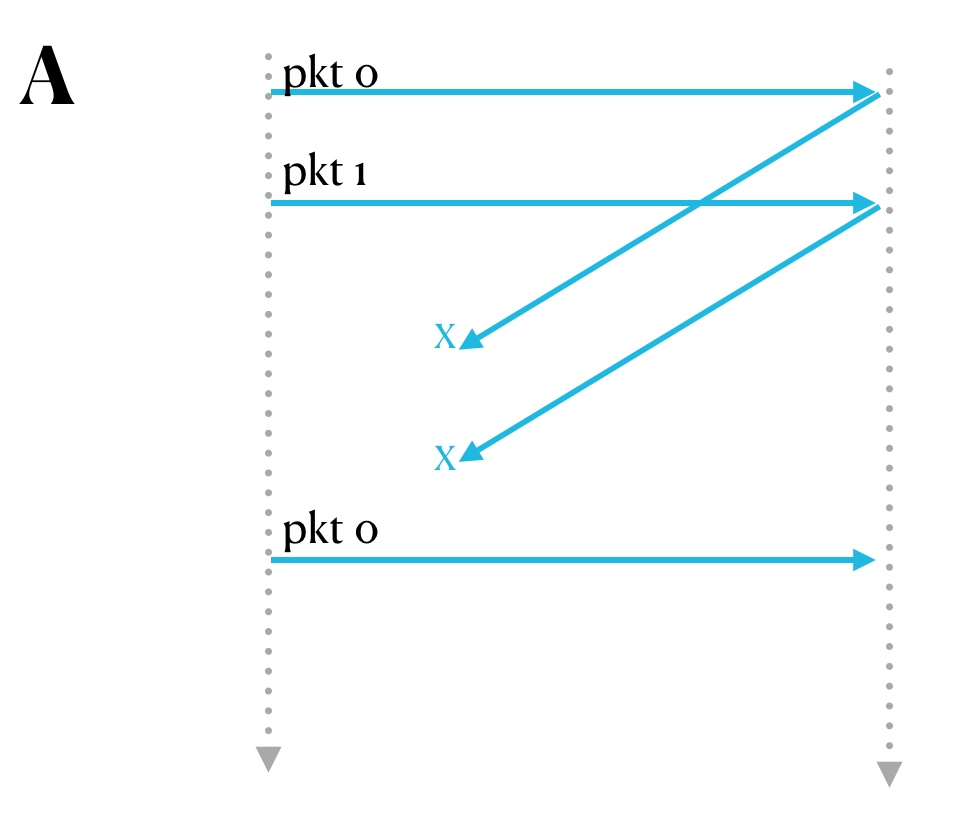

这样就解决问题了。
书上给出了一个结论:对于选择重传协议来说,滑动窗口大小必须小于等于序列号个数的一半。
到这,本文开头的三个假设只剩下这个:「数据总是按照发送的顺序被接收者接收的」。
但往往现实可能是这样的: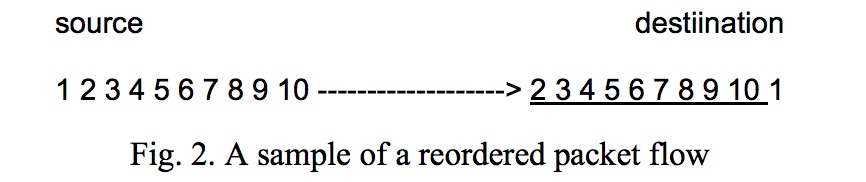
本来就会因数据丢包或数据对应的 ACK 丢失,而会出现不少重传的数据包。
再加上 packet reordering 的影响,重传的数据包变更多,降低了性能。
好了,对于「如何设计一个可靠数据传输协议」这个问题的讨论就此为止。在此基础上,再去学习 TCP 会比较好。
后记
啰里八嗦讲了上面一大堆,主要是让自己有个机会复习这部分内容。回想当初学习这块内容时,并没有上述这样一个循序渐进的体验,而是上来就是看 TCP 的定义,再看首部内容等等,学得自己满头包,学习效率可想而知。
希望自己以后的学习也能尽量遵循「循序渐进」的原则。
另外,自己花了点时间,把 CS144 这门课的 Lab 做完了。
有几个小心得,想在这里提一下:
首先就是配环境,
我一开始的时候按他这个推荐的方法试了,最后没成功。甲骨文的这个 VirtualBox 感觉很不好用。恰巧,VMware Fusion Player Version 12 对个人使用免费了,我就采用方法 3,自己再去下个 Ubuntu 20 LTS,对着下面这个表,一个一个装就是了。
当时花了一大半个下午加一个晚上,差点就在这第一步的时候放弃了。
第二个容易放弃的点是你遇到 Lab4 的时候,Lab 4 是挺难的。但在准备过测试的时候,建议可以开个国外的主机,把代码放到那上面跑,因为有好像有些测试用例是对国外的网站发起请求。如果还是出现 timeout 的错误,那就得检查自己的代码了。为了省钱,不开也行,那就多在本地上多跑几次测试看看。我自己在本地跑测试,出现过 97% Pass、98 % Pass、 99% Pass 和 100% Pass。这时候就要活用控制变量法了。
CS 144 的课程视频在 YouTube 上也有,但我自己看下来感觉还是:读课本是主要手段,辅以这 2013 年的课程视频。
144_lab_code 这是我自己完成整个 Lab 的代码,加了不少注释,希望能有些帮助。